
科普:我们人眼看到连续画面的帧数为 24 帧,大约 0.04 秒,低于 0.04 就会卡成 ppt。电影胶片是 24 帧 也就是每秒钟可以看到 24 张图像 低于这个数值就会感觉画面不流畅 所以以 24 帧为界限
先把源视频文件转换成图片,在用 API 面部识别进行融合更换面部内容变成其他图形,并且利用软件完成对源文件音频的提取,再次把更换过的图片转换成为视频,并和音频进行融合。
FFmpeg 官网
使用实例:
需要的库文件:
opencv-python
pillow(PIL)
subprocess
在此使用旷视科技的人脸识别 API 进行完成。先对图片进行脸部识别并进行融合,看这里:
这就得注册并且拥有自己的 API key 进行 API 调用了
代码如下:
import requests
import simplejson
import json
import base64
def find_face(imgfile):
print("finding")
http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'
data = {"api_key": 'nFnE8LQ32lteRvt99pA-sGCG9PRkGI',
"api_secret": '0RD-G7z9LNEmdyua4WDdd7xxxxIuTs', "image_file": imgfile, "return_landmark": 1}
files = {"image_file": open(imgfile, "rb")}
response = requests.post(http_url, data=data, files=files)
req_con = response.content.decode('utf-8') #decode将已编码的json字符串解码成python对象
req_dict = json.JSONDecoder().decode(req_con)
this_json = simplejson.dumps(req_dict) #将Python对象编码成JSON字符串
this_json2 = simplejson.loads(this_json) #将已编码的 JSON 字符串解码为 Python 对象
faces = this_json2['faces']
# print(faces)
list0 = faces[0]
rectangle = list0['face_rectangle']
# print(rectangle)
return rectangle
# find_face()
def merge_face(img_url_1,img_url_2,img_url_3,number):
ff1 = find_face(img_url_1)
ff2 = find_face(img_url_2)
rectangle1 = str(str(ff1['top']) + "," + str(ff1['left']) + "," + str(ff1['width']) + "," + str(ff1['height']))
rectangle2 = str(ff2['top']) + "," + str(ff2['left']) + "," + str(ff2['width']) + "," + str(ff2['height'])
url_add = "https://api-cn.faceplusplus.com/imagepp/v1/mergeface"
f1 = open(img_url_1, 'rb')
f1_64 = base64.b64encode(f1.read())
f1.close()
f2 = open(img_url_2, 'rb')
f2_64 = base64.b64encode(f2.read())
f2.close()
data = {"api_key": 'nFnE8LQ32ltevt99pA-kaMGG9PRkGI', "api_secret": '0RD-G7z9LNExxxxQaIuTs',
"template_base64": f1_64, "template_rectangle": rectangle1,
"merge_base64": f2_64, "merge_rectangle": rectangle2, "merge_rate": number}
response = requests.post(url_add, data=data)
req_con = response.content.decode('utf-8')
req_dict = json.JSONDecoder().decode(req_con)
result = req_dict['result']
imgdata = base64.b64decode(result)
file = open(img_url_3, 'wb')
file.write(imgdata)
file.close()
import os
def test():
image1 = "guan.jpg" #图2的脸会换到图1上
image2 = "cjz.jpg"
image3 = "1234.png"
try:
merge_face(image1,image2,image3,100)
except:
pass
test()
这是效果图:

如果是我的脸换到朴信惠或者关晓彤任何一个人脸上会出现违和感,在此就不展示了。
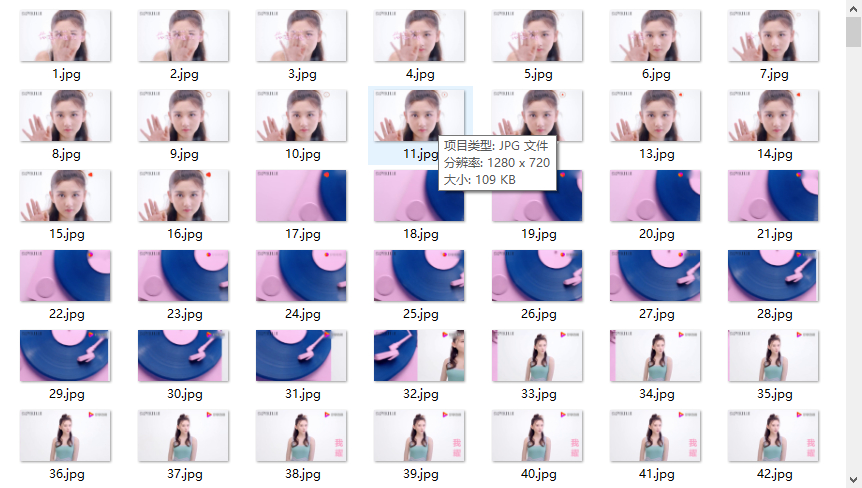
# 将视频拆分成图片
def video2txt_jpg():
vc=cv2.VideoCapture("test.mp4")
c=1
if vc.isOpened():
r, frame=vc.read()
if not os.path.exists('images'):
os.mkdir('images')
os.chdir('images')
else:
r=False
while r:
cv2.imwrite(str(c) + '.jpg', frame)
# txt2image() # 同时转换为ascii图
r, frame=vc.read()
c+=1
os.chdir('..')
return vc
video2txt_jpg()
可以得出如下:
def jpg2video():
fourcc=VideoWriter_fourcc(*"MJPG")
fps = 24
outfile_name = 'test11'
images=os.listdir('images')
im=Image.open('images/' + images[0])
vw=cv2.VideoWriter(outfile_name + '.avi', fourcc, fps, im.size)
os.chdir('images')
for image in range(len(images)):
# Image.open(str(image)+'.jpg').convert("RGB").save(str(image)+'.jpg')
frame=cv2.imread(str(image + 1) + '.jpg')
vw.write(frame)
# print(str(image + 1) + '.jpg' + ' finished')
os.chdir('..')
vw.release()
如下:

# 调用ffmpeg获取mp3音频文件
def video2mp3():
outfile_name= 'ccc' + '.mp3'
subprocess.call('ffmpeg -i ' + "test.MP4" + ' -f mp3 ' + outfile_name, shell=True)
如下是提取过程:
def video_add_mp3():
outfile_name= 'ccc-txt.mp4'
subprocess.call('ffmpeg -i ' + 'test11.avi' + ' -i ' + "ccc.mp3" + ' -strict -2 -f mp4 ' + outfile_name, shell=True)
video_add_mp3()
到此分拆步骤完成,接下来整合成一个 APP 进行工作
#!/usr/bin/python
# -*- coding: utf-8 -*-
# @Time : 2019/9/1 8:50
# @Author : cuijianzhe
# @File : AI换脸.py
# @Software: PyCharm
import requests
import simplejson
import json
import base64
import argparse
import os
import cv2
import subprocess
from cv2 import VideoWriter, VideoWriter_fourcc, imread, resize
from PIL import Image, ImageFont, ImageDraw
## 面部识别
def find_face(imgfile):
print("finding")
http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'
data = {"api_key": 'nFnE8LxxxxMGCG9PRkGI',
"api_secret": '0RD-G7z9LxxxxrSmq7vxIuTs', "image_url": imgfile, "return_landmark": 1}
files = {"image_file": open(imgfile, "rb")}
response = requests.post(http_url, data=data, files=files)
req_con = response.content.decode('utf-8')
req_dict = json.JSONDecoder().decode(req_con)
this_json = simplejson.dumps(req_dict)
this_json2 = simplejson.loads(this_json)
faces = this_json2['faces']
list0 = faces[0]
rectangle = list0['face_rectangle']
# print(rectangle)
return rectangle
#number表示换脸的相似度
def merge_face(image_url_1,image_url_2,image_url_3,number):
ff1 = find_face(image_url_1)
ff2 = find_face(image_url_2)
rectangle1 = str(str(ff1['top']) + "," + str(ff1['left']) + "," + str(ff1['width']) + "," + str(ff1['height']))
rectangle2 = str(ff2['top']) + "," + str(ff2['left']) + "," + str(ff2['width']) + "," + str(ff2['height'])
url_add = "https://api-cn.faceplusplus.com/imagepp/v1/mergeface"
f1 = open(image_url_1, 'rb')
f1_64 = base64.b64encode(f1.read())
f1.close()
f2 = open(image_url_2, 'rb')
f2_64 = base64.b64encode(f2.read())
f2.close()
data = {"api_key": 'nFnx3xxxxGI', "api_secret": '0RD-G7z9xxxxxQaIuTs',
"template_base64": f1_64, "template_rectangle": rectangle1,
"merge_base64": f2_64, "merge_rectangle": rectangle2, "merge_rate": number}
response = requests.post(url_add, data=data)
req_con = response.content.decode('utf-8')
req_dict = json.JSONDecoder().decode(req_con)
result = req_dict['result']
imgdata = base64.b64decode(result)
file = open(image_url_2, 'wb')
file.write(imgdata)
file.close()
def test(filename):
image1 = "pxh.png"
image2 = filename
image = filename
try:
merge_face(image2,image1,image,90)
except:
pass
# 将视频拆分成图片
def video2txt_jpg(file_name):
vc=cv2.VideoCapture(file_name)
c=1
if vc.isOpened():
r, frame=vc.read()
if not os.path.exists('Cache'):
os.mkdir('Cache')
os.chdir('Cache')
else:
r=False
while r:
cv2.imwrite(str(c) + '.jpg', frame)
# txt2image() # 同时转换为ascii图
test('./Cache/'+str(c) + '.jpg')
r, frame=vc.read()
c+=1
os.chdir('..')
return vc
# 将图片合成视频
def jpg2video(outfile_name, fps):
fourcc=VideoWriter_fourcc(*"MJPG")
images=os.listdir('Cache')
im=Image.open('Cache/' + images[0])
vw=cv2.VideoWriter(outfile_name + '.avi', fourcc, fps, im.size)
os.chdir('Cache')
for image in range(len(images)):
# Image.open(str(image)+'.jpg').convert("RGB").save(str(image)+'.jpg')
frame=cv2.imread(str(image + 1) + '.jpg')
vw.write(frame)
# print(str(image + 1) + '.jpg' + ' finished')
os.chdir('..')
vw.release()
# 调用ffmpeg获取mp3音频文件
def video2mp3(file_name):
outfile_name=file_name.split('.')[0] + '.mp3'
subprocess.call('ffmpeg -i ' + file_name + ' -f mp3 ' + outfile_name, shell=True)
# 合成音频和视频文件
def video_add_mp3(file_name, mp3_file):
outfile_name=file_name.split('.')[0] + '-txt.mp4'
subprocess.call('ffmpeg -i ' + file_name + ' -i ' + mp3_file + ' -strict -2 -f mp4 ' + outfile_name, shell=True)
def find_face(imgfile):
print("finding")
http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect'
data = {"api_key": 'nFnE8LxxxxRkGI',
"api_secret": '0RD-G7xxxxxPJSmq7vQaIuTs', "image_url": imgfile, "return_landmark": 1}
files = {"image_file": open(imgfile, "rb")}
response = requests.post(http_url, data=data, files=files)
req_con = response.content.decode('utf-8')
req_dict = json.JSONDecoder().decode(req_con)
this_json = simplejson.dumps(req_dict)
this_json2 = simplejson.loads(this_json)
faces = this_json2['faces']
list0 = faces[0]
rectangle = list0['face_rectangle']
# print(rectangle)
return rectangle
#number表示换脸的相似度
def merge_face(image_url_1,image_url_2,image_url_3,number):
ff1 = find_face(image_url_1)
ff2 = find_face(image_url_2)
rectangle1 = str(str(ff1['top']) + "," + str(ff1['left']) + "," + str(ff1['width']) + "," + str(ff1['height']))
rectangle2 = str(ff2['top']) + "," + str(ff2['left']) + "," + str(ff2['width']) + "," + str(ff2['height'])
url_add = "https://api-cn.faceplusplus.com/imagepp/v1/mergeface"
f1 = open(image_url_1, 'rb')
f1_64 = base64.b64encode(f1.read())
f1.close()
f2 = open(image_url_2, 'rb')
f2_64 = base64.b64encode(f2.read())
f2.close()
data = {"api_key": 'nFnE8LxxxxxxxPRkGI', "api_secret": '0RD-G7zxxxxxxQaIuTs',
"template_base64": f1_64, "template_rectangle": rectangle1,
"merge_base64": f2_64, "merge_rectangle": rectangle2, "merge_rate": number}
response = requests.post(url_add, data=data)
req_con = response.content.decode('utf-8')
req_dict = json.JSONDecoder().decode(req_con)
result = req_dict['result']
imgdata = base64.b64decode(result)
file = open(image_url_3, 'wb')
file.write(imgdata)
file.close()
import os
def test(filename):
image1 = "pxh.jpg"
image2 = filename
image3 = filename
try:
merge_face(image2,image1,image3,90)
except:
pass
def main():
# test('./Cache/8.jpg')
for root,dir,files in os.walk('./Cache'):
for file in files:
filename = os.path.join(root,file)
# print(filename)
test(filename)
if __name__ == '__main__':
INPUT="test.mp4"
FPS=24
vc=video2txt_jpg(INPUT)
FPS=vc.get(cv2.CAP_PROP_FPS) # 获取帧率
vc.release()
main()
jpg2video(INPUT.split('.')[0], FPS)
print(INPUT, INPUT.split('.')[0] + '.mp3')
video2mp3(INPUT)
video_add_mp3(INPUT.split('.')[0] + '.avi', INPUT.split('.')[0] + '.mp3')
在视频截图中的最终效果看起来不怎么好,看来应该是面部特征越明显才能融合越好。不过目前是实现了从宋祖儿---> 朴信惠换脸术,


 邯城往事
邯城往事