****# 虽然没什么用,学习阶段,练手。
import requests
from bs4 import BeautifulSoup
import threading
glock = threading.Lock()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
'Referer': 'https://hacpai.com/login'}
class get_doutu():
def all_htmls(self):
htmls = []
for i in range(1,10):
url = "https://www.doutula.com/photo/list/?page=%s"%i
res = requests.get(url,headers=headers)
htmls.append(res.text)
return htmls
def html_parser(self):
datas = []
for html in self.all_htmls():
soup = BeautifulSoup(html,'lxml')
img_data = soup.find_all('img',attrs={'class' : 'img-responsive lazy image_dta'})
for data in img_data:
datas.append((data['alt'],data['data-original']))
return datas
def Download_img(self):
for idx, (title, img_url) in enumerate(self.html_parser()):
post_fix = img_url[-3:]
filename = f"./image/{title}.{post_fix}"
print(idx, filename)
img_info = requests.get(img_url)
with open(filename, "wb")as f:
f.write(img_info.content)
if __name__ == "__main__":
doutu = get_doutu()
doutu.Download_img()
参考:
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#find-all
#!/usr/bin/python
# -*- coding: utf-8 -*-
# @Time : 2020/5/1 16:11
# @Author : cuijianzhe
# @File : biaoqingbao.py
# @Software: PyCharm
import threading
import requests
from bs4 import BeautifulSoup
import re
class Download_picture():
def download_all_htmls(self):
htmls = []
for num in range(1,5):
url = "https://fabiaoqing.com/biaoqing/lists/page/%s.html"%(num)
r = requests.get(url)
htmls.append(r.text)
return htmls
def html_parser(self):
"""
解析单个HTML,得到数据
@return list((img_title, img_url))
"""
img_divs = []
for html in self.download_all_htmls():
soup = BeautifulSoup(html, 'html.parser')
img_divs.extend(soup.find_all("div", class_="tagbqppdiv"))
datas = []
for img_div in img_divs:
img_node = img_div.find("img")
if not img_node: continue
datas.append((img_node["title"], img_node["data-original"]))
return datas
def get_picture(self):
for idx,(title,img_url) in enumerate(self.html_parser()):
# 移除标点符号,只保留中文、大小写字母和阿拉伯数字
reg = "[^0-9A-Za-z\u4e00-\u9fa5]"
title = re.sub(reg, '', title)
# 发现了超长的图片标题,做截断
if len(title) > 10: title = title[:10]
# 得到jpg还是gif后缀
post_fix = img_url[-3:]
filename = f"./output/{title}.{post_fix}"
print(idx, filename)
img_data = requests.get(img_url)
with open(filename, "wb")as f:
f.write(img_data.content)
if __name__ == "__main__":
get_biaoqingbao = Download_picture()
for m in range(3): #创建3个线程
thread = threading.Thread(target=get_biaoqingbao.get_picture())
thread.start()
import requests
import re
html = requests.get('https://hacpai.com/top/general').text
result = re.findall('class="fn-flex-1".*?aria-name="(.*?)".*?href="(.*?)".*?',html,flags=re.S)
#paihang_str = str(result)
for value in result:
name, url = value
tup1 = name.replace("/"," "),url
tup2 = ' '.join(tup1)
print(tup2)
with open('paihangbang.txt','a',encoding='utf-8') as f:
f.write(tup2)
**效果如下:**
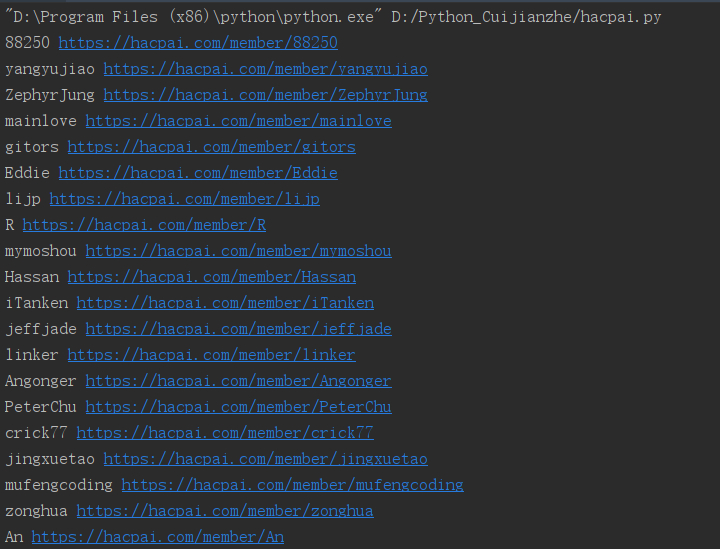
import requests
import re
content = requests.get('https://movie.douban.com/chart').text
# 豆瓣电影排行榜
pattern = re.compile('class="pl2".*?<.*?="(.*?)".*?>(.*?)<span.*?>(.*?)</span>.*?"rating_nums">(.*?)</span>.*?"pl">(.*?)</span>', re.S)
# compile可以在多次使用中提高效率,这里影响不大
results = re.findall(pattern, content)
for result in results:
url, name1, name2, nums, pl = result
print(url, name1.replace("/","").strip(), name2.replace("/","").strip(), nums, pl)
import requests
from fake_useragent import UserAgent
headers = {
'Referer': 'https://hacpai.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
data = {
"nameOrEmail":"cuijianzhe",
"userPassword":"54949cdcbe4d252ba3400897883df589811",
"captcha":""
}
request = requests.session()
base_url = "https://hacpai.com/login"
res = requests.post(base_url,headers=headers,json=data)
res.raise_for_status()
print(res.text)
#http://music.163.com/song/media/outer/url?id=1377519494 #对外开放的下载接口
import requests
import urllib.request #进行网络数据下载到本地
from fake_useragent import UserAgent
import re
def getResponse(url,headers):
'''
:return: html信息
'''
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response
return None
except:
return None
if __name__ == '__main__':
url = 'https://music.163.com/song?id=1377519494'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
res = getResponse(url,headers)
res
print(res.text)
歌曲名信息:

……
def getSongName(songid):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
url = 'https://music.163.com/song?id={}'.format(songid)
Text = getResponse(url,headers=headers).text
titile = re.findall('<title>(.*?)</title>',Text,re.S)
name = titile[0].split('-')[0]
return name.strip()
……
if __name__ == '__main__':
name = getSongName(1377519494)
print(name)
获取歌曲名称:

……
if __name__ == '__main__':
songid = input('请输入要下载的歌曲id:')
url = 'http://music.163.com/song/media/outer/url?id={}.mp3'.format(songid)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
down_url = getResponse(url,headers).url
SongName = getSongName(songid)
urllib.request.urlretrieve(down_url,SongName+'.mp3')
……
下载成功:
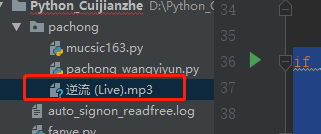
import requests
import urllib.request #进行网络数据下载到本地
from fake_useragent import UserAgent
import re
def getResponse(url,headers):
'''
:return: html信息
'''
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response
return None
except:
return None
def getSongName(songid):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
url = 'https://music.163.com/song?id={}'.format(songid)
Text = getResponse(url,headers=headers).text
titile = re.findall('<title>(.*?)</title>',Text,re.S)
name = titile[0].split('-')[0]
return name.strip()
if __name__ == '__main__':
songid = input('请输入要下载的歌曲id:')
url = 'http://music.163.com/song/media/outer/url?id={}.mp3'.format(songid)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
down_url = getResponse(url,headers).url
SongName = getSongName(songid)
urllib.request.urlretrieve(down_url,SongName+'.mp3') #网上歌曲映射到本地
import requests
import re
from multiprocessing import Pool
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
#todo:下载整个歌单网站信息
def get_page(url):
res = requests.get(url,headers=headers)
data = re.findall('<a title="(.*?)" href="/playlist\?id=(\d+)" .*?</a>',res.text)
print(data)
pool = Pool(4)
pool.map(get_songs,data)
#todo:获取整个歌单歌曲并进行下载
def get_songs(data):
playlist_url = 'https://music.163.com/playlist?id=%s'%data[1]
res = requests.get(playlist_url,headers=headers)
for i in re.findall('<a href="/song\?id=(\d+)">(.*?)</a>',res.text):
down_url = 'http://music.163.com/song/media/outer/url?id=%s'%i[0]
print(down_url)
try:
with open('./music/'+i[1]+'.mp3','wb') as f:
f.write(requests.get(down_url,headers=headers).content)
except:
pass
if __name__ == '__main__':
playlist_url = 'https://music.163.com/discover/playlist/?order=hot'
get_page(playlist_url)
import requests
import re
from multiprocessing import Pool
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
}
music_list = []
def get_page(url):
res = (requests.get(url,headers=headers)).text
data = re.findall('<a title="(.*?)" class="tit s-fc0" href="/playlist\?id=(\d+)"',res)
print(data)
pool = Pool(4)
pool.map(get_song,data)
def get_song(data):
gedan_url = 'https://music.163.com//playlist?id=%s'%data[1]
res = requests.get(gedan_url,headers=headers)
for i in re.findall('<a href="/song\?id=(\d+)">(.*?)</a>',res.text):
down_url = 'http://music.163.com/song/media/outer/url?id=%s'%i[0]
print(down_url)
try:
with open("./music/"+i[1]+".mp3","wb") as f:
f.write(requests.get(down_url,headers=headers).content)
except:
pass
if __name__ == '__main__':
my_url = 'https://music.163.com/discover'
get_page(my_url)
 邯城往事
邯城往事